

When faced with a textbook example of a problem solvable by algorithms, data professionals often rush to apply their favorite algorithm without questioning the initial problem formulation. The old adage rings true: “If your only tool is a hammer, every problem looks like a nail.”
The same article has been previously published in finnish
When businesses start to use data in decision-making and optimization, defining the problem is one of the most error-prone parts of the development process. The problem and data determine the built solution and its operation. Hence, data-utilizing projects can be impacted by what I call the “you get what you pay for” phenomenon.
How does the "you get what you pay for" problem show itself?
The success of data projects is directly influenced by the data utilized.
Cliched as they may be, the maxims about the impact of data quality on algorithm performance have deeply ingrained themselves in the minds of business decision-makers. In reality, “data quality” is a concept not fully understood by many. In all its complexity, the criteria for data quality are clearest to data professionals who understand what to demand from data and what to expect from it. These same data-savvy professionals may be blind to another stumbling block in data projects—incorrect problem definition.
When a textbook example of an algorithm-solvable problem presents itself, even these professionals often rush to their notebooks. They should pause to consider whether the problem to be solved has been correctly set, even in cases that sound simple. Here the saying holds true among data professionals as well: “If your only tool is a hammer, every problem looks like a nail.”
Example of an incorrectly defined problem
Let’s examine two example cases. Both address the same challenge: How to reduce churn.

Many companies have attempted to predict the turnover of paying customers (churn/attrition). Often, the idea is this: identify customers who are reducing or stopping their use of the service and target them with preventive actions, such as communications or offers.
Forecasting customer turnover is exactly the kind of challenge that many data scientists drool over! Initially, it might sound like a useful and interesting case for data collection, but the problem formulation in the project contains a dangerous trap.
If we analyze business needs more broadly, we realize that the ultimate goal is to minimize customer turnover, not to predict it. The original problem definition did not hit the mark immediately but instead led to hastily solving the wrong issue.
But what harm does incorrect problem framing actually cause? If we start predicting customer turnover instead of minimizing it, the model built will likely learn to identify user groups at risk of leaving as intended. However, this approach also creates significant problems:
- The model predicting churn tells us that customers are at risk of leaving but cannot directly say why.
The model's output generalizes all departing users into the same category. Different customer groups at risk of leaving require different actions to improve customer relations, but the model in its current form does not enable distinguishing between them.
A pertinent example of incorrect risk classification is classifying the so-called sleeping customers. This group may include subscribers to a service whose subscription is running as expected, and no problems have occurred. These customers haven’t thought about the ongoing charge or canceling the subscription. As a thought experiment, the model could interpret such passivity as a sign of dissatisfaction and incorrectly place a well-functioning customer relationship in the danger zone. In the worst case, the company takes action and launches a targeted marketing campaign that annoys the customers and leads them to cancel the entire service—even though they had been completely satisfied until now. - In some cases, the model functions exactly as it should, predicting departure with certainty—and nothing can be done. Some customers may indeed be lost cases, regardless of whether they are targeted with actions or not. The model works, but actually, no customer relationship management does. Money is wasted on actions, but no results are produced.
- When the model is designed, it is often considered which signals could classify a user as “in the danger zone.” Frequently, only user-created signals, such as those generated by using the service, are chosen. However, in designing models that solve this type of problem setting, actions from the service towards the user are rarely considered. When the prediction model is utilized, the analysis-based actions taken towards customers contaminate the data.
Suppose that a grocery delivery service’s customer service representative reviews loyalty accounts identified by the model as at risk of leaving. The customer service representative notices that some at-risk accounts had delivery problems and as a corrective action he slips them all discount coupons. As a result, customers remain service users, but the model does not understand the reason behind the customers’ retention. When the model is retrained with new data, similar cases may no longer be classified in the same way, because according to the model’s data, delivery issues did not cause the churn.
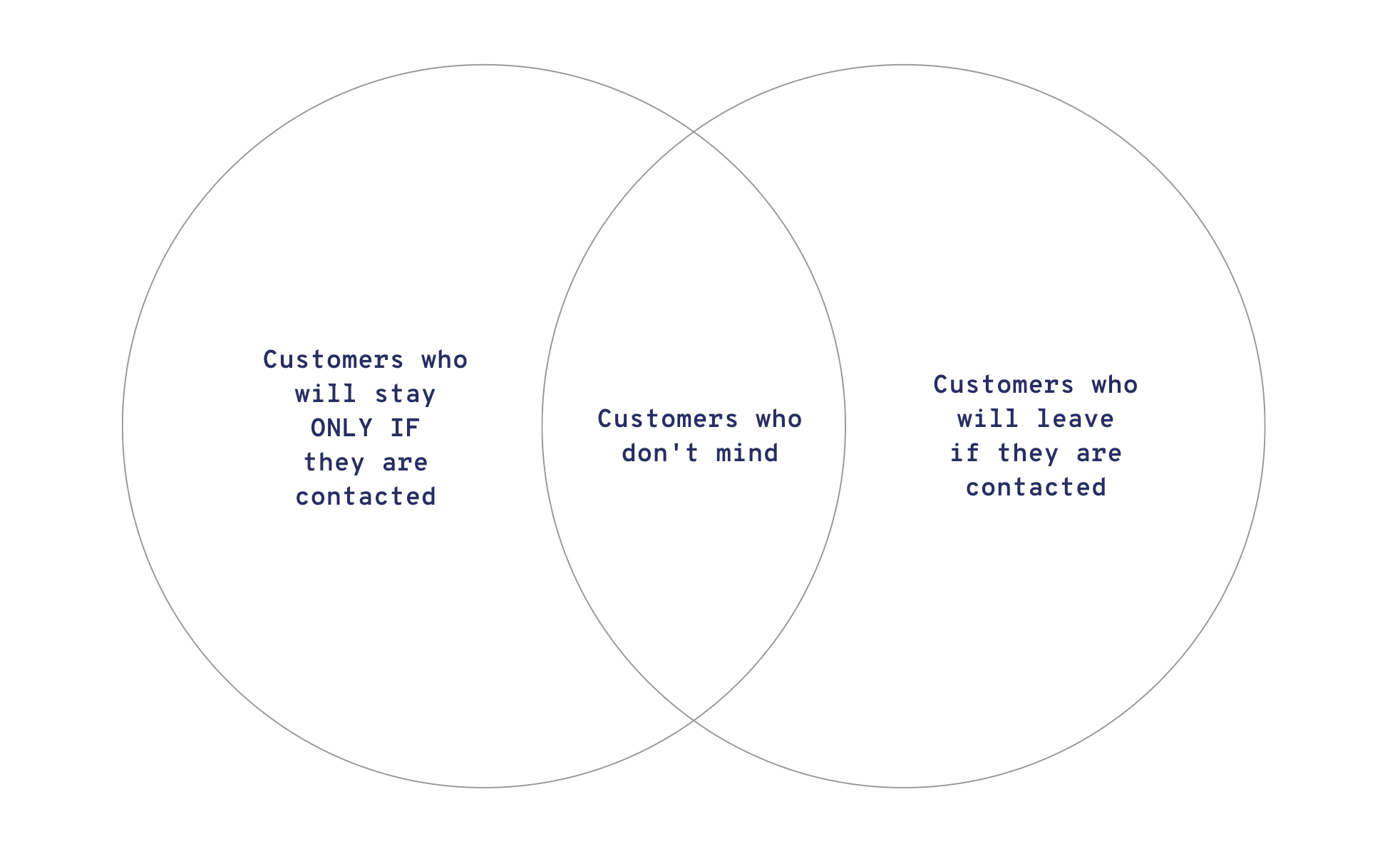
How can the “you get what you pay for” problem be turned into an advantage?

Design the problem chain from start to finish and consider what you want to achieve.
“You get what you pay for” is not only a constant challenge in data projects but also a fundamental nature guiding their successful implementation. Defining the problem and objectives goes a long way.
Changing the problem to be solved also changes the utilization approach. Ultimately, this may be the most challenging part of implementing a great algorithm, as people must also trust the machine’s assessment of actions, even if it feels intuitively wrong.
The problem should be defined from the beginning to depict the desired outcome, not an intermediary stage. In our example case, the right solution would be to build a model that predicts the best possible way to manage customer relationships, revealing what kind of treatment satisfied and dissatisfied customers really need. Changing the problem to be solved also changes the utilization approach. Ultimately, this could be the most challenging part of adopting the new algorithm, as people must trust the machine’s evaluation of actions, even if it seems counterintuitive.
Concretely, a small change in problem definition significantly alters the entire task’s outcomes. In our example case, comparing two different problem descriptions is relatively straightforward; we no longer aim to simply divide the entire customer base binary, but make personalized decisions for different customers.
Additionally, we shift the assessment of effects to be processed by algorithms rather than burdening people with it. In some situations, it may be possible to automate certain customer relationship management methods in the same pipeline, thereby further reducing the workload on people.
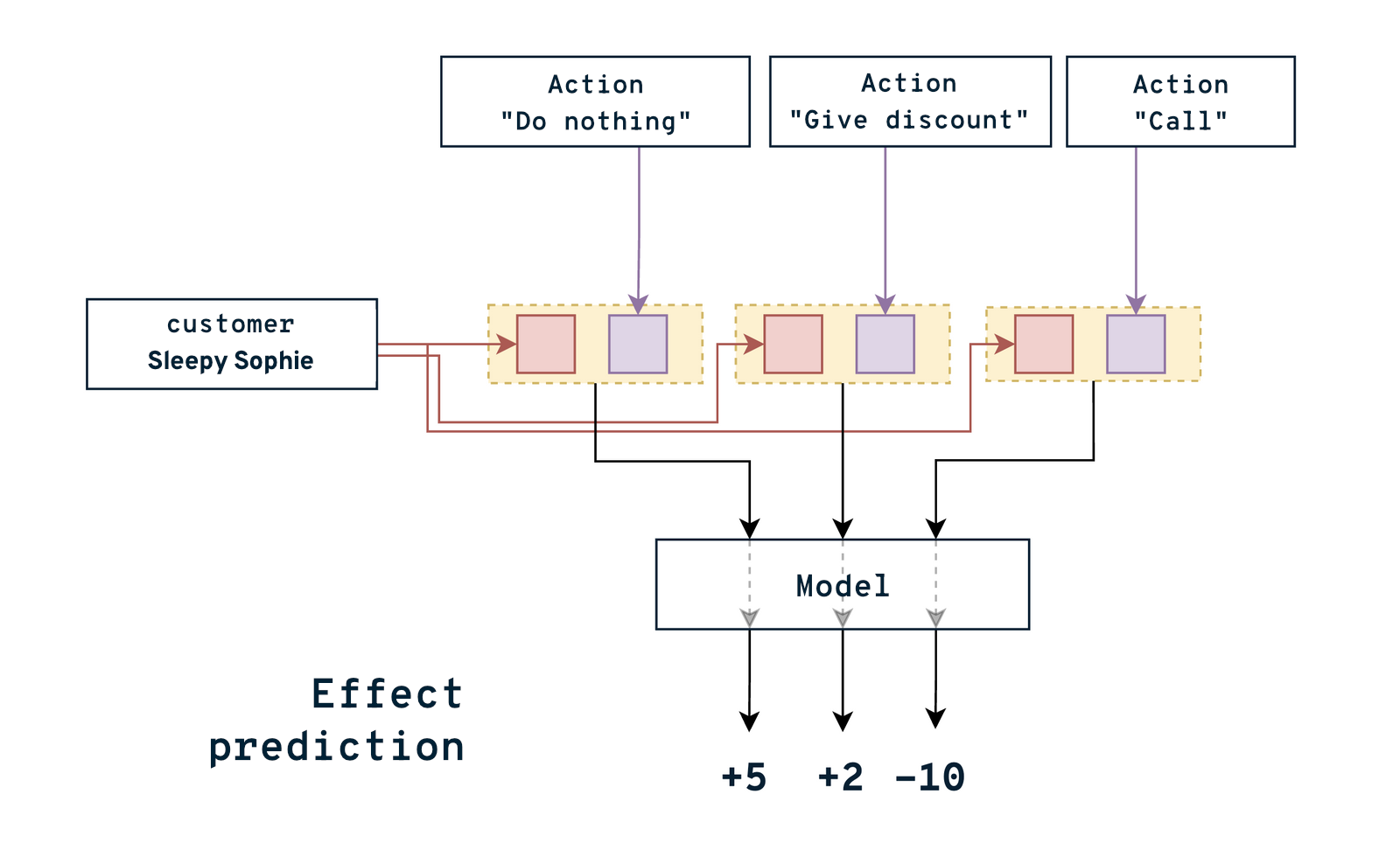
One challenge in the first example was that customer relationship management actions contaminated the data, making the results unreliable. In this case, the model is specifically created for assessing customer relationship management, so it learns from successful and failed actions to become a better predictor. The model can evaluate the effects of various management approaches on the customer and identify which actions are best for each customer at different times. The model might identify that the best approach for most customers could simply be to leave them alone. The previous model could not do this and might have incorrectly presented them as being at risk of leaving.
The simple solution to the “you get what you pay for” problem: change your order.
In a nutshell: how do I “get what I pay for” and benefit from it?
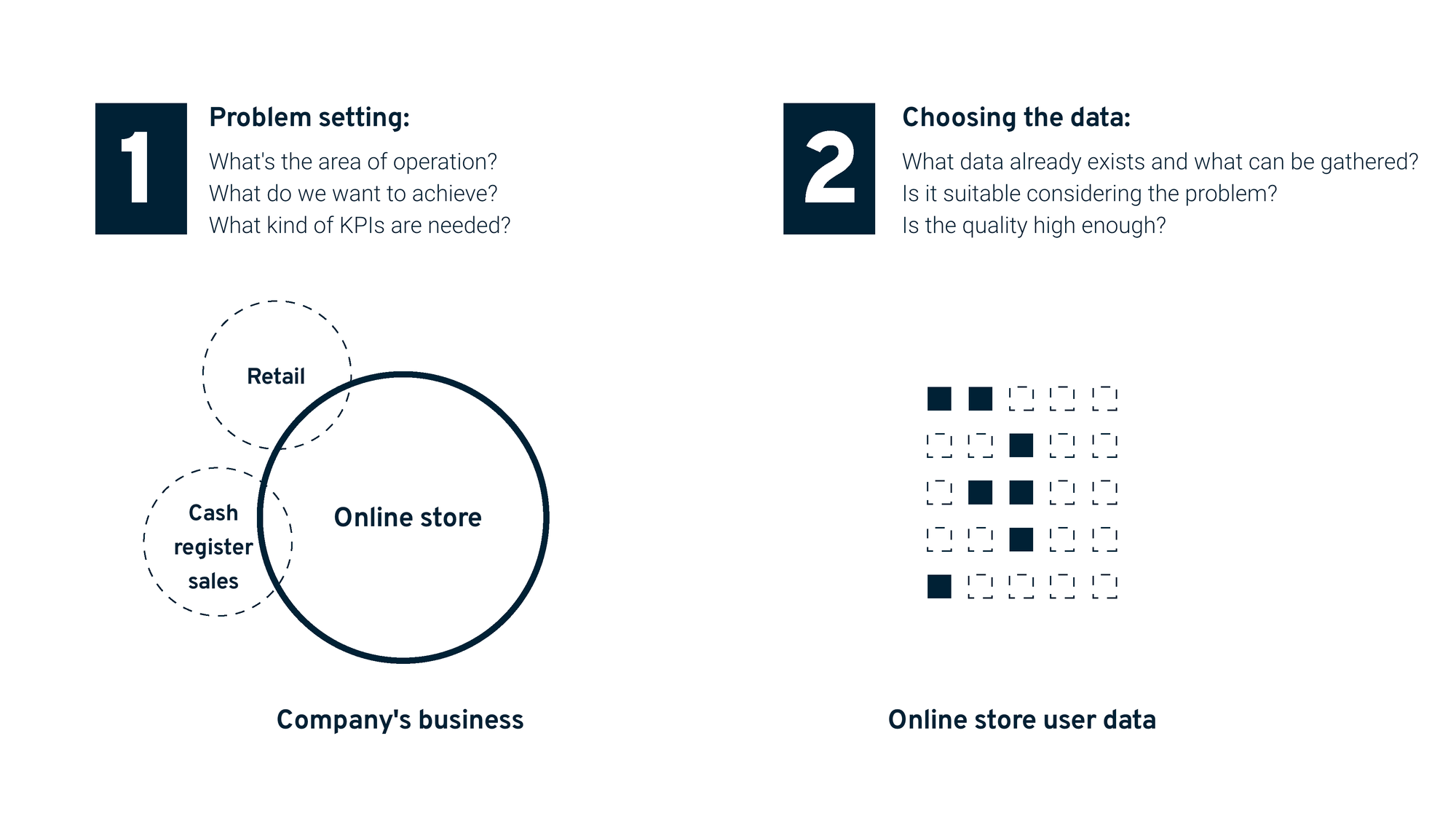
- PROBLEM. Spend time defining the problem and ensure you are addressing the right issue. A simple flowchart can be a good tool for defining objectives, operational areas, available data, and desired outcomes.
- DATA. Ensure that you are collecting data on aspects that are crucially related to customer relationships and your defined objectives. If data is not yet available, can it be collected?
- TEST. Initially, testing can be done “on paper.” A good guideline is to consider: “Does this outcome directly help solve the original problem?” Even “hard” models can be tested up to production alongside business operations without too much disruption.
There is a simple solution to the “you get what you pay for” problem: if the project does not produce the desired result, change what you order. In our example, the issue was minimizing customer churn. However, because of the methods used, such as utilizing existing data and optimizing metrics, this problem often recurs in various algorithmic solutions. Therefore, it is crucial to recognize the risk posed by hasty problem definition and try to circumvent it.
Emblica is a technology company focused on data-intensive applications and artificial intelligence. Our customers are e.g. Sanoma, Uponor, Caruna, and the Tax Administration. Emblica is 100% owned by its employees.